42sh – APPSINGES
Cela fait maintenant plusieurs mois que le C est derrière nous, et nombreux sont les APPSINGES qui ne savent même plus qu’est-ce qu’un pointeur.
Je vais donc essayer de résumer dans ce document les grandes parties du travail à fournir pour 42sh.
42sh est donc un projet long, difficile et contenant un maximum de code (pour avoir un 42sh pleinement fonctionnel, n’espérez pas taper moins de 5000 lignes de code).
Il est composé de 5 grandes parties qui sont les suivantes :
Le lexeur – Permet de découper le code sh fourni au programme
L’AST – Un Abstract Syntax Tree (arbre de syntaxe abstrait), il s’agit d’un conteneur qui nous permettra de stocker le code shell en mémoire dans un format pratique à exécuter
Le parseur – C’est lui qui va lire le code shell découpé par le lexeur et générer un AST
L’exécuteur – Il s’agit du cœur de l’application, il va exécuter chaque instruction de l’AST.
Le readline – L’interface entre l’utilisateur et 42sh, elle va permettre d’entrer des commande, de « naviguer » dans la commande avec les flèches directionnelles, remonter dans l’historique des commandes, etc.
Ce document étant destiné à un publique averti sur les méthodes et la pédagogie EPITA, je ne m’étendrais pas sur ce qu’est un shell, le langage C, et essayerait de fournir le moins de code possible pour éviter qu’il soit considéré comme de la triche.
1. Le lexeur
Comme dit plus haut, il s’agit du module permettant de découper le code shell fourni. Pour ce faire, nous allons utiliser la grammaire LL fournie dans le sujet.
Une fois que vous l’aurez lu, vous aurez vite identifié les « symboles » qui vont vous permettre de découper le code, en voici quelques uns : ‘\n’ ‘;’ ‘&’ ‘&&’ ‘||’ ‘␣’ etc...
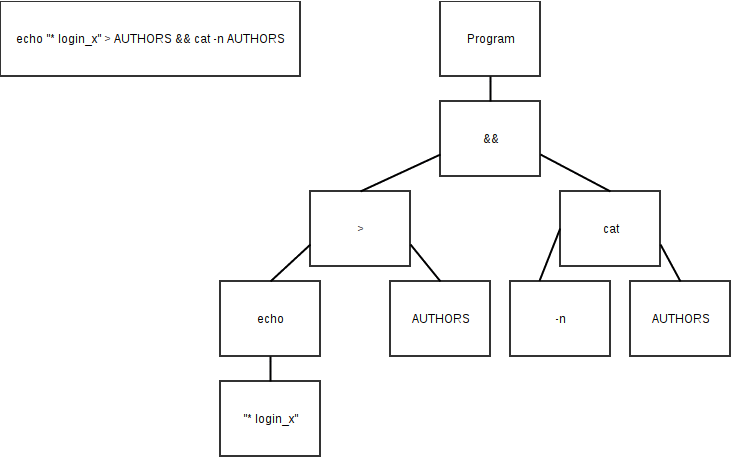
Prenons par exemple le code sh suivant : echo " * login_x" >> AUTHORS
Le lexeur devra fournir la liste de symboles suivante :
["echo", "\" * login_x\"", ">>", "AUTHORS"]
La première chose qu’on remarque, c’est qu’il y a des séparateurs à ne pas inclure dans la liste, et d’autres à inclure, je vous laisser chercher lesquels.
Lors du parsing, nous n’aurons jamais besoin de revenir en arrière dans le lexeur, par contre il sera souvent utile de connaître le token suivant. Pour ces 2 raisons, le plus simple et le plus pratique est encore d’implémenter une liste chaînée de tokens.
Certaines fonctions vous seront donc utiles par la suite :
get_token() – qui renvoie le token actuel
eat() – passe au token suivant
get_next_token() – pour récupérer le suivant
Il faut aussi bien sûr des fonctions pour remplir le lexeur mais ça c’est votre problème.
2. L’AST
Comme dit plus haut, il s’agit de la représentation en mémoire de votre code. Vous ne pourrez donc pas le tester tant que vous n’aurez pas fini le parseur, qui va générer l’AST à partir des symboles contenus dans le lexeur.
Pour ceux qui ne savent vraiment pas ce que c’est, voici à quoi ça pourrait ressembler
Il existe sans doute de nombreuses implémentations possibles pour cette structure de données en C, mais je n’en présenterai ici qu’une seule.
Tout d’abord il faut une struct fourre-tout, pour pouvoir boucler facilement dessus par la suite, par exemple :
struct ast_node
{
enum node_type type; // le type de nœud
void *expression; // permet de stocker un pointeur vers n’importe quoi et donc d’effectuer des cast implicites
}
Ensuite, il faut reprendre la grammaire LL fournie dans le sujet, et faire une struct par expression possible.
Par exemple, pour gérer le if, on pourrait avoir le code suivant :
struct if_expression
{
struct ast_node *condition ;
struct ast_node *body ;
}
Il faudra bien sûr étoffer cette struct pour gérer les else et elif.
3. Le parseur
Une fois l’AST terminé, il faut maintenant le construire. Pour ce faire, nous allons utiliser le lexeur et analyser chaque symbole l’un après l’autre pour savoir dans quelle type d’expression on se trouve.
La structure du parseur est bien évidement récursive, pour reprendre l’exemple de la if_expression, vous allez parser le body en faisant quelque chose comme :
struct ast_node *create_ast(struct lexer lexer)
{
// …
parse_if(lexer);
}
struct ast_node *parse_if(struct lexer lexer)
{
struct if_expression *ie = malloc(sizeof (struct if_expression));
lexer_eat(lexer); // On skip le mot-clé if
ie->condition = create_ast(lexer);
lexer_eat(lexer); // On skip le mot-clé then
ie->body = create_ast(lexer);
// …
}
4. L’exécution
En gros, il faut redescendre dans l’arbre créé et l’exécuter, cette fois pas de bout de code d’exemple demerdez-vous avez votre implem. Mais vous vous en doutez sûrement, si le parsing est récursif, l’éxécution l’est aussi.
5. Le readline
RTFM
Bonne chance :)